Hello there. In this blog, I will show you few approaches to
do sound sampling in C language.
I will not be taking WAV, MP3, or any other file formats,
instead I will generate numbers randomly and use it as a sound input. Reason
because I am not using WAV or any other format because the main purpose of this
blog is to see how we can process big chunk of data in just few seconds with
System efficiency. By system efficiency I mean, using resource of a System like
Memory and CPU as low as possible. So, Let’s Begin with some basics.
Basics
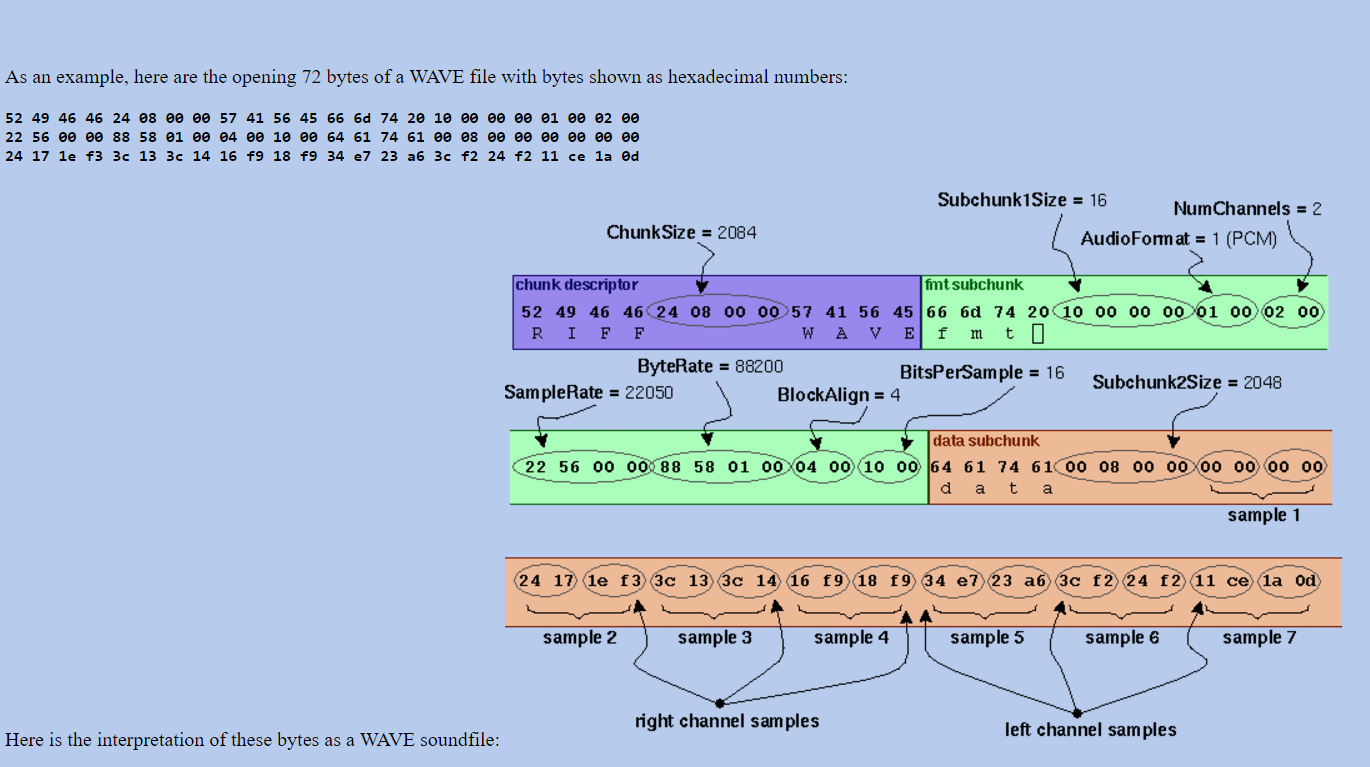
 Above is the Header information of the Wav file. Until the byte 44, all
the information is related to specification of the Wav file. Actual samples
start after byte 45.
Above is the Header information of the Wav file. Until the byte 44, all
the information is related to specification of the Wav file. Actual samples
start after byte 45.

What Exactly I am going to do?
Simple Approach
Code:
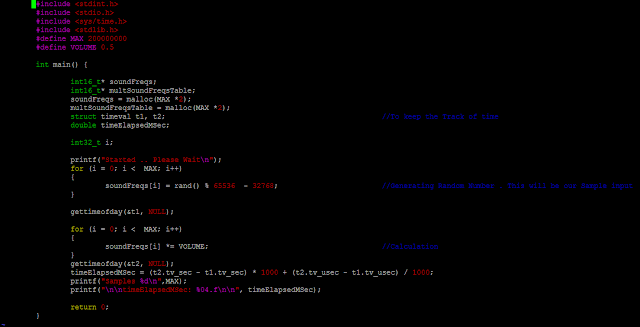
Compiler Argument: gcc
-O1 -o output program.c

I am going through few approaches to build different
algorithms. But question is what exactly I am going to do? I will code three
different approaches adjusting the volume of a sequence of sound samples. Here,
I will have 20,00,00,000 length of 16bit signed integer array
which will have values between -32768 to 32767 as my sound samples. I will have to calculate those sound samples by the Volume . This is like user is adjusting volume on a device.
Simple Approach
Code:

Compiler Argument: gcc
-O1 -o output program.c
This code is simple approach and following is the result.
Optimization
|
Time Elapsed (mSecond)
|
Memory Usage (MB)
|
|---|---|---|
| 0 | 741 | 391.996 |
| 1 | 261 | 392.160 |
| 2 | 268 | 392.160 |
| 3 | 229 | 392.160 |
Above table shows when I use optimization level 3 , program’s
elapsed time decreased by 30% and Memory usage fairly stays the same.
Compiler Argument to see Memory and CPU usage : “command time -v ./output “.
Below is the screen shout of how output looks like.

Table Look Up
In table look up approach, I pre-calculated the samples from
0 to 32768 by Volume.
This is the code:


For this approach the elapsed time and memory usage were significantly
changed. This algorithm take more time and memory than simple approach.
Optimization
|
Time Elapsed (Second)
|
Memory Usage (MB)
|
|---|---|---|
| 0 | 2.121 | 782.284 |
| 1 | 1.180 | 782.760 |
| 2 | 1.117 | 782.760 |
| 3 | 1.117 | 782.856 |
Memoization
In this approach, main purpose is to eliminate repeating
calculations. Once we calculate a sample by Volume factor, we store it in the
array and next time use it instead of Multiplying.
Below is how code looks like.


Optimization
|
Time Elapsed (Second)
|
Memory Usage (MB)
|
|---|---|---|
| 0 | 2.847 | 782.692 |
| 1 | 0.679 | 782.764 |
| 2 | 0.547 | 782.736 |
| 3 | 0.545 | 782.760 |
This approach cost us less time compare to the table lookup.
In average, out of 20,00,00,000 total samples only 41,905 time calculation happen
and all the other values just got copied from an array . So, this is the fairly
improvement in terms of CPU stress.